HDFS的balancer命令详解以及执行命令threads quota is exceeded报错解决 前言 用Hadoop集群一点时间时,HDFS节点间的数据不平衡,尤其在新增和下架节点、或者人为干预副本数量的时候,多的达到70%,少的40%。出现这种状况,我们一般采用HDFS自带的balancer工具来解决,保证每个节点的数据分布均衡。 balancer命令 balancer 123456# start: start-balancer.sh #用默认的10%的阈值启动balan 2018-03-15 Hadoop troubleshooting
Leetcode633:平方数之和 题目平方数之和 给定一个非负整数 c ,你要判断是否存在两个整数 a 和 b,使得 $a^2+b^2$ = c。 123输入: 5输出: True解释: 1 * 1 + 2 * 2 = 5 双指针解法12345678910111213141516171819202122class judgeSquareSum{ public boolean judgeSquareSum(in 2018-01-15 Leetcode 双指针 esay
Leetcode118:杨辉三角 题目杨辉三角 给定一个非负整数 numRows,生成杨辉三角的前 numRows 行。 示例 123456789输入: 5输出:[ [1], [1,1], [1,2,1], [1,3,3,1], [1,4,6,4,1]] 解法一12345678910111213141516171819class Solution { public List<List& 2018-01-08 Leetcode esay
Sqoop遇到问题汇总 MySQL数据导入Hive时数值类型全部为null mysql通过sqoop导入到hive表中,发现有个别数据类型为int或tinyint的列导入后数据为null。设置各种行分隔符,列分隔符都没有效果 解决方法尝试一: hive中单独将有问题的那几列的数据类型设置为string类型,重新导入后发现,里面的值变成true或者false。 尝试二: 由此猜想,sqoop在导入的时候,将那几列的数据 2018-01-08 Sqoop fixbug
Leetcode1:两数之和 题目两数之和 给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标。你可以假设每种输入只会对应一个答案。但是,数组中同一个元素不能使用两遍。 示例 1234给定 nums = [2, 7, 11, 15], target = 9因为 nums[0] + nums[1] = 2 + 7 = 9所以返回 [0, 1] 解法一 思 2018-01-01 Leetcode 双指针 esay
数仓工具hive(六):Hive中常用函数汇总 常用日期函数12345678910111213141516171819unix_timestamp:返回当前或指定时间的时间戳 from_uni xtime:将时间戳转为日期格式current_date:当前日期current_timestamp:当前的日期加时间to_date:抽取日期部分year:获取年month:获取月day:获取日hour:获取时minute:获取分second:获取 2017-08-18 Hive 总结
Hive50道sql必练题 前言50道Hive之sql必练题,做完50道题会对HiveSql有一个比较深的认识,且附上答案以及验证结果。 建表12345678-- 学生表create table student(s_id string,s_name string,s_birth string,s_sex string) row format delimited fields terminated by '\,';-- 课堂表 2017-07-22 Hive 练习
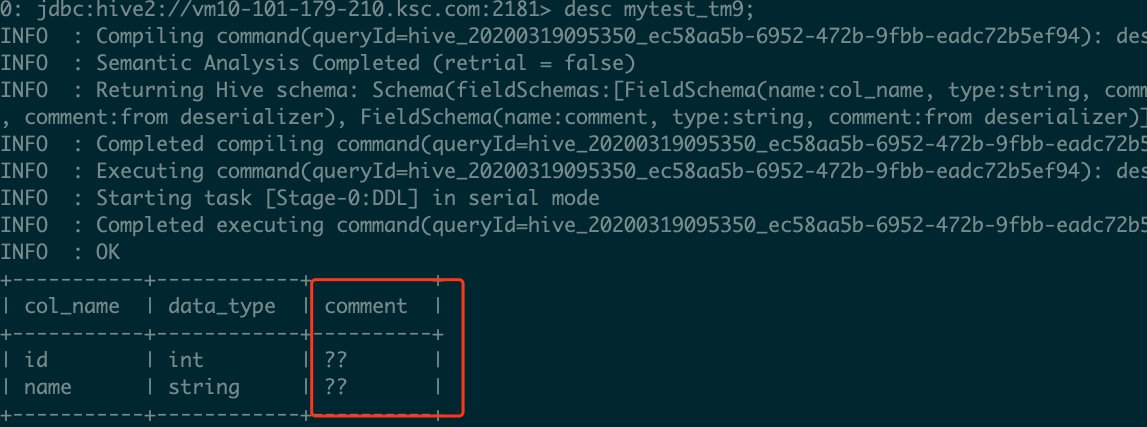
Ambari+HDP安装的Hive出现中文乱码解决 前言公司决定使用Ambari+HDP这一套大数据运维加部署框架去替代CDH,遇到一些问题会及时记录下来 Hive注释comment出现乱码Hive建表语句1234567create table test.mytest_tm1( id int comment'编号', name string comment '名字' ) 2017-07-21 Hive ambari
30个python入门基础小练习 30个python入门基础小练习1. 重复元素判定以下方法可以检查给定列表是不是存在重复元素,它会使用 set() 函数来移除所有重复元素。 12345678def all_unique(lst): return len(lst) == len(set(lst))x = [1,1,2,2,3,2,3,4,5,6]y = [1,2,3,4,5]all_unique(x)all_unique(y 2017-06-30 Python practice
数仓工具hive(四):Hive文件存储格式以及优缺点 前言Hive支持的存储数的格式主要有:TEXTFILE 、SEQUENCEFILE、ORC、PARQUET。 行与列存储的特点行存储的特点查询满足条件的一整行数据的时候,列存储则需要去每个聚集的字段找到对应的每个列的值,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度更快。 列存储的特点因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每 2017-06-04 Hive hive存储策略